
TL;DR:
- A mesterséges intelligencia modellek tanítása nem automatikus folyamat, hanem többfázisú, üzleti adatokon alapuló fejlesztés. A tanítás során a modell mintákat tanul fel, nem másol, hanem generalizál, különösen a tokenizáció és különböző tanulási típusok alkalmazásával. A helyes adatgyűjtéssel, finomhangolással és jogszabályi megfeleléssel hatékonyan lehet vállalati AI-t építeni kis- és középvállalkozások számára is.
Sok vállalatvezető hallott már az AI modellek tanításáról, de ha megkérdezik, mit jelent ez pontosan, a legtöbben valami homályos képet festenek: “betanítják az algoritmust” vagy “rengeteg adatot kap a rendszer.” Mi az ai modellek tanítása valójában? Nem egy automatikus folyamat, amit egyszer elindítasz és kész. Ez egy gondosan tervezett, több fázisból álló fejlesztési folyamat, amelynek során a modell az üzleti adataidból tanul döntési mintákat. Ez a cikk lépésenként mutatja be ezt a folyamatot, hogy pontosan értsd, hogyan épül fel egy vállalatra szabott mesterséges intelligencia.
Tartalomjegyzék
- Mi az AI modellek tanítása és alapfogalmai
- A gépi tanulás folyamata és megbízhatóságának biztosítása
- Módszerek és technológiák a nagy nyelvi modellek (LLM) finomhangolásában
- Az egyedi üzleti igényekhez igazított adatgyűjtés és előkészítés
- Szoftveres környezet és hardverigények a praktikus AI tanításhoz
- Gyakorlati lépések az AI modell tanítás során kis- és középvállalatoknak
- Miért félreértett az AI modellek tanítása és hogyan közelítsük meg helyesen
- Hogyan segít a Stratify az ön vállalatának az AI modellek tanításában
- Gyakran ismételt kérdések az AI modellek tanításáról
Fő Tanulságok
| Pont | Részletek |
|---|---|
| AI modellek tanítása | Az AI modellek tanítása statisztikai mintázatok felismerésén alapul nagy adatkészleteken. |
| Gépi tanulási lépések | A tanítás 6 jól definiált lépésből áll, amelyek együtt biztosítják a megbízható működést. |
| Finomhangolási technológiák | LoRA és QLoRA ma a legköltséghatékonyabb módszerek kisebb GPU-kon is. |
| Minőségi adatfontosság | A jó minőségű, domain-specifikus adat lényegesebb, mint a nagy mennyiség. |
| Jogszabályi megfelelés | Az EU AI Act szabályozza az AI használatát, amire a magyar KKV-knak is fel kell készülniük. |
Mi az AI modellek tanítása és alapfogalmai
A mesterséges intelligencia nem szabályokat követ. Nem mondod neki, hogy “ha az ügyfél ezt írja, akkor azt válaszold.” Helyette megmutatod neki több ezer példát, és a modell önmaga fedezi fel a mintákat. Ez az alapvető különbség egy hagyományos szoftver és egy AI modell között.
Az AI modellek nagy adathalmazokon tanulnak mintákat az új tartalom generálásához. A tanítás során a rendszer statisztikai összefüggéseket épít fel: melyik szó után melyik szó a legvalószínűbb, melyik termékleírás milyen vásárlói viselkedéssel jár együtt, melyik gyártási paraméter megelőzi a meghibásodást. Nem másolja az adatokat, hanem általánosít belőlük.
A vállalati AI tanítás alapjai között kiemelkedik a tokenizáció fogalma. A nyelvi modellek nem szavakat, hanem tokeneket dolgoznak fel: ezek lehetnek szavak, szótöredékek, vagy akár egyedi karakterek. Egy 7B paraméteres modell (vagyis 7 milliárd belső “súllyal” rendelkező rendszer) ezeket a tokeneket és azok összefüggéseit tanulja meg.
Az AI modellek oktatása során érdemes ismerni a főbb tanulási típusokat:
- Felügyelt tanulás (supervised learning): Megjelölt adatokból tanul. Például ügyfélpanaszokat kategóriákba sorolsz, és a modell megtanulja ezt a besorolást.
- Felügyelet nélküli tanulás: Nincs előre megadott kategória. A modell maga csoportosítja az adatokat, például vásárlói szegmenseket azonosít.
- Megerősítéses tanulás (reinforcement learning): A modell jutalmakat és büntetéseket kap döntéseiért, és ezek alapján javítja viselkedését.
- Transzfer tanulás: Egy már betanított modellt használunk kiindulópontként, és csak az üzleti feladatra hangoljuk tovább. Ez a leggyakoribb módszer KKV környezetben.
Ez utóbbi különösen fontos: nem kell nulláról felépíteni egy modellt. A transzfer tanulás az ai modellek fejlesztése terén az egyik leghatékonyabb eszköz, mert meglévő, nagy modellekre építve adja az üzleti tudást.
A gépi tanulás folyamata és megbízhatóságának biztosítása
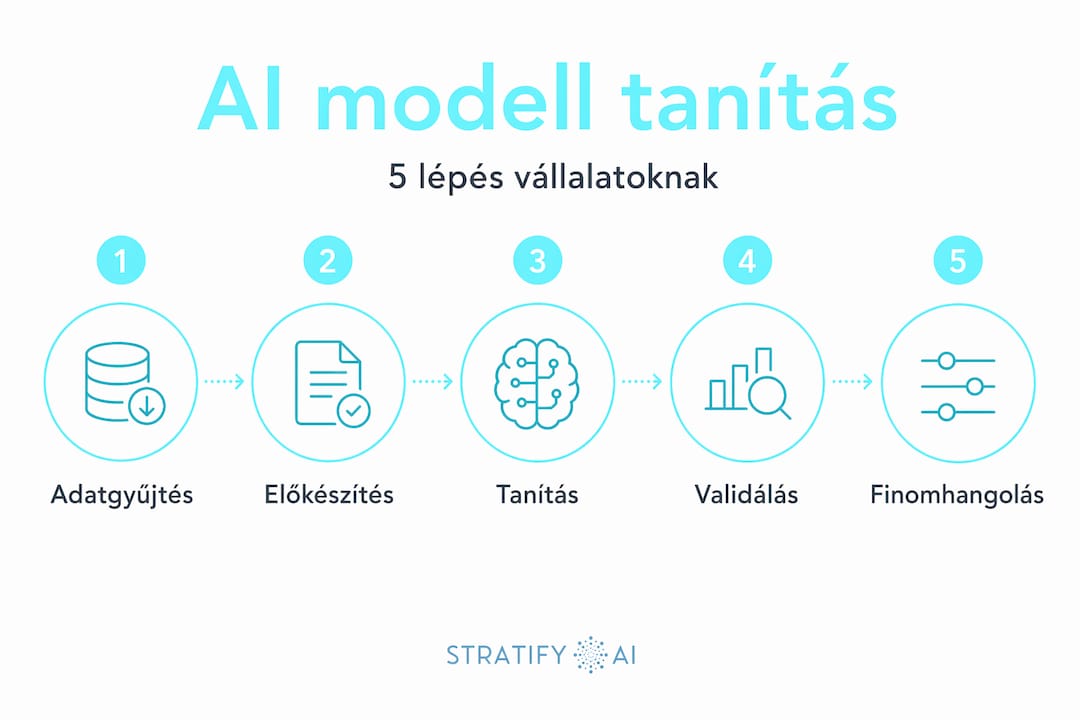
A gépi tanulás 6 kulcslépése biztosítja a modell pontosságát láthatatlan adatokon. Ezeket a lépéseket nem szabad felcserélni vagy kihagyni, mert minden fázis az előző eredményére épít.
A gépi tanulás folyamatai a következő sorrendben zajlanak:
- Adatelőkészítés: Az adatok megtisztítása, hiányos értékek pótlása, formátumok egységesítése. Ez tipikusan az összes munka 60-70%-a.
- Modellválasztás: Melyik architektúra illik legjobban a feladathoz? Szövegfelismeréshez más kell, mint előrejelzéshez.
- Tanítás: A modell futtatása az adatokon, a paraméterek folyamatos finomítása a hibák minimalizálása érdekében.
- Validáció: A modell teljesítményének mérése olyan adatokon, amelyeket a tanítás során nem látott.
- Optimalizálás: Hiperparaméterek (például tanulási ráta, batch méret) hangolása a jobb teljesítmény érdekében.
- Értékelés és deployment: A végső modell tesztelése valós körülmények között, majd éles üzembe helyezése.
A gépi tanulás lépései során az egyik legveszélyesebb hiba a túlillesztés (overfitting). Ez azt jelenti, hogy a modell “bemagolta” a tanítási adatokat, de valós, eddig nem látott esetekben gyengén teljesít. Képzeld el, hogy egy értékesítő csak az általa már ismert ügyfelekkel boldogul, idegenekkel viszont nem tud mit kezdeni.
A megbízható AI modell nem az, amelyik a legmagasabb pontszámot éri el a tanítási adatokon, hanem az, amelyik egyenletesen jól teljesít valós üzleti helyzetekben.
Az adatok helyes felosztása kritikus: általában a példák 80-90%-a megy tanításra, 10-20%-a validációra. A két halmaz között nincs átfedés, különben hamis képet kapunk a teljesítményről.
Módszerek és technológiák a nagy nyelvi modellek (LLM) finomhangolásában

Az ai modellek fejlesztése az elmúlt két évben forradalmi változáson ment át. Ma már nem kell millió eurós infrastruktúra ahhoz, hogy egy vállalat saját, testreszabott nyelvi modellt üzemeltessen. Ezt a LoRA és QLoRA technológiák tették lehetővé.
A LoRA és QLoRA technikák a paraméterek 99%-át lecsökkentve gyorsítják a finomhangolást, miközben közel teljes minőséget tartanak meg. A LoRA (Low-Rank Adaptation) lényege: a teljes modellt nem módosítjuk, csak kis “adapter” mátrixokat adunk hozzá, amelyek megtanulják a céges specifikus tudást. Olyan, mintha egy tapasztalt szakértőre bővítési modult illesztenél rá, ahelyett hogy teljesen átképzenéd.
A QLoRA 75%-kal csökkenti a VRAM szükségletet, így 6-8 GB-os fogyasztói GPU-kon is elvégezhető a 7B-es modell finomhangolása. Ez KKV szempontból azt jelenti, hogy egy hozzáférhető hardveren is futtatható a tanítás, nem szükséges drága szerverfarm.
| Jellemző | LoRA | QLoRA |
|---|---|---|
| Memóriaigény (7B modellnél) | 16-24 GB VRAM | 6-8 GB VRAM |
| Várható teljesítmény | 90-95% az alap modellhez képest | 80-90% az alap modellhez képest |
| Tanítási idő (felhőben) | 30-60 perc | 45-90 perc |
| Ajánlott GPU | RTX 3090, 4090 | RTX 3060-tól |
| Ideális felhasználás | Erőforrás-gazdag környezet | Közepes hardver, KKV |
A finomhangolási technikák LLM esetén megválasztásakor figyelni kell a modell méretére is. A kis- és középvállalatok számára jellemzően a 7B-8B paraméteres modellek (például Mistral 7B, LLaMA 3.1 8B) a legjobb egyensúlyt kínálják teljesítmény és erőforrásigény között. A 2026-os modelltípusok között már számos, kifejezetten vállalati finomhangolásra optimalizált változat elérhető.
A finomhangolás során ezekre érdemes figyelni:
- A tanulási rátát (learning rate) kellően alacsonyra kell beállítani, tipikusan 1e-4 és 3e-4 közé.
- Az epochok száma (hányszor megy át a modell az összes adaton) 2-4 között optimális a legtöbb céges feladatnál.
- A batch méret és a gradient accumulation együtt határozza meg a tényleges tanítási sebességet.
- Monitorozd a validációs loss értékét folyamatosan: ha ez elkezd nőni, miközben a tanítási loss csökken, megkezdődött a túlillesztés.
Profi tipp: Mindig végezz validációs értékelést (például MMLU benchmarkot) a finomhangolás során és után, hogy meggyőződj arról, a modell általános képességei megmaradtak, nem csak a szűk céges feladatban lett jobb.
Az egyedi üzleti igényekhez igazított adatgyűjtés és előkészítés
Az ai modellek tanítása pontosan annyira jó, amennyire az adatok jók. Ez nem közhely: meglepő, hogy milyen sok projekt bukik el nem az algoritmus, hanem a zajos, hiányos vagy rosszul strukturált adatok miatt.
A Magyar KKV-knak általában 1000-5000 domain-specifikus példát érdemes használni JSONL formátumban, 90/10 tanuló/validáció aránnyal. A felhőben a tanítás költsége jellemzően 50-500 EUR között alakul. Ez nem valami elképzelhetetlen összeg, különösen ha figyelembe vesszük, hogy egy testreszabott AI megoldás hónapok alatt megtérítheti önmagát.
Az adatgyűjtés és előkészítés AI-hoz a következő lépésekből áll:
- Releváns adatok azonosítása: Melyek azok az üzleti folyamatok, ahol a legtöbb dokumentált eset, interakció vagy döntés elérhető? Ügyfélszolgálati emailek, szerződések, technikai leírások, gyártási naplók.
- Adattisztítás: Duplikátumok eltávolítása, hibás karakterek javítása, egységes formátum kialakítása.
- Annotálás: Ha felügyelt tanulásról van szó, az adatokat meg kell jelölni. Például: ez az ügyfélüzenet “panasz”, ez “ajánlatkérés”, ez “visszajelzés”.
- JSONL formátum kialakítása: Ez a legelterjedtebb formátum az LLM finomhangoláshoz. Minden sor egy önálló JSON objektum, amely tartalmaz egy “prompt” és egy “completion” mezőt.
- Adatszétválasztás: A 90/10-es arány nem ökölszabály, de általában jól működik. Kisebb adathalmaznál (1000 példa alatt) érdemes 80/20-at alkalmazni.
Profi tipp: Nem a mennyiség, hanem a minőség számít. 500 gondosan megírt, reprezentatív példa többet ér, mint 5000 zajos, ellentmondásos rekord. Az “eye test” módszer bevált: olvasd végig véletlenszerűen kiválasztott adatsorokat, és döntsd el, te magad tanulnál-e belőlük helyesen.
Szoftveres környezet és hardverigények a praktikus AI tanításhoz
A fogyasztói kategóriás GPU-k (RTX 3060-tól a 4090-ig) és cloud szolgáltatók alkalmassá tették a KKV méretű AI tréninget: könnyen kezelhetően, elfogadható költséggel. Ez 2023 előtt még nem volt igaz. Ma egy jól konfigurált felhős futtatással nemcsak olcsóbb, hanem rugalmasabb is a tanítás.
A szoftveres eszközök terén ezeket érdemes ismerni:
- Unsloth: Kifejezetten LoRA/QLoRA finomhangolásra optimalizált, 2-4-szeres gyorsítást nyújt más keretrendszerekhez képest.
- TRL (Transformer Reinforcement Learning): A HuggingFace karbantartja, jól dokumentált, széles modellsupport.
- Axolotl: Rugalmas konfigurációs fájl alapú megközelítés, különböző feladattípusokhoz jól testreszabható.
A hardver- és jogszabályi követelmények AI-hoz nem választhatók el egymástól. Az EU AI Act keretrendszer előírja a kockázatmenedzsmentet és a dokumentációt a tanítás során, különösen magyarországi cégek esetében.
A megfelelőség szempontjából a következő lépéseket kell elvégezni:
- Azonosítsd az AI rendszer kockázati kategóriáját (alacsony, közepes, magas).
- Dokumentáld az adatforrásokat, az adatkezelési folyamatokat és a tanítási paramétereket.
- Vezess rendszeres auditálást a modellek teljesítményéről és torzítási kockázatairól.
- Biztosítsd az emberi felügyeletet a magas kockázatú döntéseknél.
- Gondoskodj az incidens-nyilvántartásról és a hibajelentési folyamatról.
A szoftveres környezet kialakításához érdemes figyelembe venni, hogy a felhős megoldások (AWS SageMaker, Google Colab Pro, RunPod) rugalmasabb skálázást tesznek lehetővé, míg a helyi GPU-k adatvédelmi szempontból előnyösebbek lehetnek érzékeny iparágakban.
Gyakorlati lépések az AI modell tanítás során kis- és középvállalatoknak
Elmélet helyett nézzük meg, hogyan néz ki ez a valóságban. Egy 150 fős magyar gyártóvállalat úgy döntött, hogy AI modellt tanít be a műszaki dokumentációk alapján, hogy a karbantartási csapat gyorsabban kapjon választ technikai kérdéseire.
Egy tipikus 7B-es modell finomhangolása 1000-5000 példából, LoRA/QLoRA használatával 30-90 perc alatt elvégezhető felhős környezetben. Ez azt jelenti, hogy már a tesztelési fázis néhány napba, nem hónapba telik.
A gyakorlati lépések AI tréninghez a következők:
- Adatgyűjtés: Gyűjtsd össze a domain-specifikus anyagokat: termékdokumentáció, karbantartási naplók, ügyfélszolgálati emailek, belső tudásbázis.
- Formázás: Alakítsd JSONL formátumra a kérdés-válasz párokat vagy utasítás-kimeneti párokat.
- Modell kiválasztása: 7B-es méretű, nyílt forráskódú modellel kezdj (Mistral 7B, LLaMA 3.1 8B).
- Tréning konfiguráció: Állítsd be a LoRA adaptereket (rank=16-32), tanulási rátát (2e-4), epochok számát (3), és aktiváld a gradient checkpointingot a memória csökkentésére.
- Monitorozás: Figyeld a validációs loss értékét: ha 2. epoch után elkezd emelkedni, állítsd le a tanítást.
- Kiértékelés: Teszteld valós üzleti kérdésekkel, amelyek nem szerepeltek a tanítási adatokban.
- Deployment: Exportáld GGUF formátumba helyi szerverre, vagy API-n keresztül tedd elérhetővé a belső rendszereknek.
Profi tipp: Az AI tréning menedzsmentjének automatizálása (például dedikált kísérletkövetési eszközökkel, mint a Weights and Biases) drasztikusan csökkenti az IT szakértők által eltöltött manuális munkaidőt, és lehetővé teszi a kísérleteredmények visszakövethetőségét.
A folyamatlépések automatizálásában az a valódi megtakarítás, hogy az embereknek csak a döntési pontokban kell beavatkozniuk, a többi futhat önállóan.
Miért félreértett az AI modellek tanítása és hogyan közelítsük meg helyesen
Az évek tapasztalata alapján elmondható: az AI projektek legtöbbje nem technikai okokból bukik meg. A modell architektúrája, a GPU, a szoftver: ezek megoldható kérdések. A valódi problémák jellemzően máshol keresendők.
Az első és leggyakoribb félreértés az, hogy az AI tanítás teljesen automatizálható. Valóban vannak AutoML eszközök, amelyek automatikusan keresik a legjobb hiperparamétereket. De senki nem automatizálja helyetted az adatgyűjtést, az annotálást, az üzleti célok pontos megfogalmazását és a végeredmény értelmezését. Ezekhez emberi szakértelem kell, és ha ezeket kihagyod, a legjobb algoritmus sem menti meg a projektet.
A második félreértés az adatmennyiség mítosza. Sok vezető azt gondolja: “ha több adatot adunk neki, biztosan jobb lesz.” Sajnos nem. A legtöbb magyar KKV nem fordít elegendő figyelmet az AI kockázatmenedzsmentre, ami a jogszabályi büntetések kockázatát növeli. Ez azért is probléma, mert a rossz minőségű adatokból betanított, ellenőrizetlen modell nemcsak hibás döntéseket hoz, hanem EU AI Act szempontból is felelősségi kérdéseket vet fel.
A harmadik félreértés a validáció elhanyagolása. Láttunk olyan projektet, ahol a modell a tanítási adatokon 95%-os pontossággal teljesített, élesben viszont sorozatosan hibázott. A valós tesztelési folyamat nem opcionális kiegészítő, hanem az egész munka értelme.
Az AI szabályozás és kockázatkezelés fontossága különösen magyar KKV kontextusban alábecsült. A 2026-os határidők valódiak, és az “majd megoldjuk, ha probléma lesz” hozzáállás itt nem működik.
Ami igazán működik: a LoRA és QLoRA technológiák valóban egyensúlyt teremtenek minőség és gazdaságosság között. Ez nem marketing ígéret, hanem mérhető tény. A kérdés nem az, hogy megengedheted-e magadnak a saját AI modellt, hanem az, hogy megengedheted-e magadnak, hogy ne csináld, miközben a versenytársaid már belevágnak.
Hogyan segít a Stratify az ön vállalatának az AI modellek tanításában
Ha eddig eljutottál ebben a cikkben, valószínűleg már van konkrét elképzelésed arról, hol és hogyan segíthetne egy testreszabott AI modell az üzletedben. A kérdés az, hogyan váltsz az elmélettől a működő megoldásig, anélkül hogy felesleges kísérletezésre és erőforrásokra pazarold az időt.
A Stratify pontosan erre a kihívásra épített szervezet. Teljes körű AI tanácsadási és megvalósítási szolgáltatást nyújtunk: az adatgyűjtés megtervezésétől a finomhangoláson át az éles üzembe helyezésig. Tapasztalt csapatunk LoRA és QLoRA technológiákkal dolgozik, és minden projektet az EU AI Act keretrendszernek megfelelően dokumentál. Nem platformhoz kötött megoldásokat kínálunk, hanem az üzleti igényeidhez legjobban illeszkedő architektúrát választjuk. A machine learning tanácsadás keretein belül gyors árajánlatot készítünk a te konkrét folyamataidra és adataidra szabva.
Gyakran ismételt kérdések az AI modellek tanításáról
Milyen mennyiségű adat szükséges egy vállalati AI modell tanításához?
Általában 1000-5000 példa szükséges a hatékony finomhangoláshoz, amelyeket 90%-ban tanításhoz, 10%-ban validációhoz ajánlott felhasználni, mindig domain-specifikus, jó minőségű adatokból.
Mi a különbség a LoRA és a QLoRA technológiák között?
A LoRA kis adapter mátrixokkal hangolja a modellt, míg a QLoRA 80-90%-os teljesítményt nyújt 4-bites kvantizációval, lényegesen kisebb memóriaigénnyel, így fogyasztói GPU-kon is futtatható.
Milyen jogszabályi előírásoknak kell megfelelni az AI modellek tanítása során Magyarországon?
A 2026 augusztus 2-i határidővel kell megfelelni az EU AI Act előírásainak, amelyek kockázatmenedzsmentet és adathasználati dokumentációt írnak elő a magas kockázatú AI rendszereknél.
Milyen technikai eszközökre van szükség a modell tanításához?
Fogyasztói GPU-k és cloud platformok (például AWS SageMaker, RunPod) megfelelő konfigurációban elegendők a vállalati méretű tanításhoz, RTX 3060-tól felfelé helyi megoldásként is alkalmazható.
Mennyi ideig tart egy AI modell finomhangolása?
Egy átlagos 7B-es modell finomhangolása LoRA vagy QLoRA technológiával 30-90 perc alatt elvégezhető megfelelő felhős GPU-n, 1000-5000 tanítási példa esetén.